AI Evals: How to evaluate your artificial intelligence component
- Published on
- — 8 min read (~3.1k tokens)
You might have heard about "evals" and Evaluation-Driven Development (EDD) when it comes to artificial intelligence implementation—we have too! For software engineers, this isn’t a new concept. We've been running automated unit and integration tests for years. Evaluating AI interactions follow the same principle: writing test-like scenarios to understand the impact of changes and prevent screwing your users. Let’s walk through our practical process for setting up those "evals."
The Challenge of Non-Determinism
Software engineering unit tests thrive on determinism: given input X, you always expect Y. AI systems, however, challenge this model - same inputs may return different outputs, due to factors such as model state, randomness, or context sensitivity. Instead of relying on strict equality checks, we must shift toward evaluating trends, distributions and similarity. The goal is to grade or score the output based on how closely it resembles an ideal result or how well it aligns with subjective criteria.
The core value of the process lies in making observations as repeatable and measurable as possible so they can be reliably compared over time.
Why an Evaluation Loop
Your product evolves, you add or modify features over time. In traditional software, a failing unit test tells you exactly where new code broke existing behavior. Those tests are executed in continuous integration pipelines (e.g. after every commit) to ensure we (developers) don’t screw things-up.
Evals play that same role for AI, think of it as unit testing for non-deterministic systems. Whether you fine-tune a model, retrain on new data, or swap a prompt, the eval tells you whether the change helped, harmed, or had no effect.
Evaluation-Driven Development focuses on an iterative approach: identifying distributions and trends rather than relying on pass/fail assertions. The goal is to understand how outputs drift over time—not to demand identical results each run. Some measurements might use grading or scoring, while others rely on defined indicators
As our feature evolves, so do the AI systems we rely on and the preferences of our users. At the end of each evaluation run, we must inspect the data, compare outcomes and incorporate user feedback - this forms our eval loop. In traditional software development, it is rare to change input or expected output of an existing test. In AI, however, this is more common, as user intentions and expectations may shift over time.
Anatomy of an AI Evaluation
Just like a unit test from software engineering, AI evaluations have four logical elements:
- Environment, You define the model and the tools accessible by the large language model.
- Inputs, You spell out the inputs and describe what constitutes an acceptable output.
- Execution, You run the system under test.
- Assessment, You score the result according to criteria that may combine hard rules, similarity measurements, or human judgment.
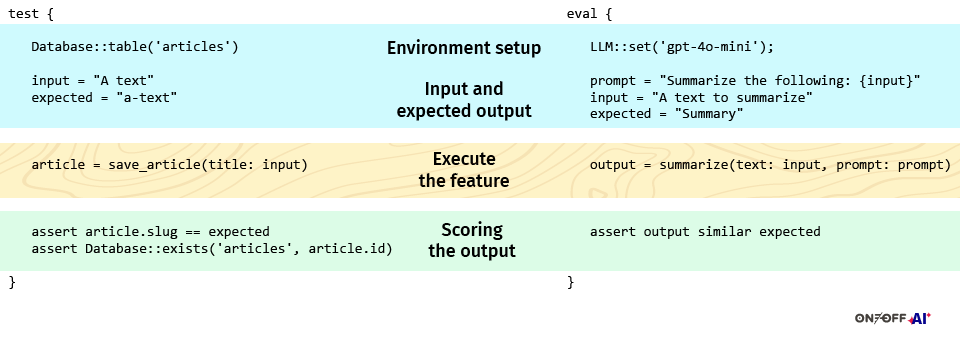
We consider the prompt as part of the inputs within our AI eval as a change in the instructions may have a relevant impact on the outputs. Similarly a database is part of the environment of a traditional unit test, the LLM model (it’s provider) and the tools available at its disposal are considered as part of the environment in which our eval runs.
Creating the Evaluation Loop
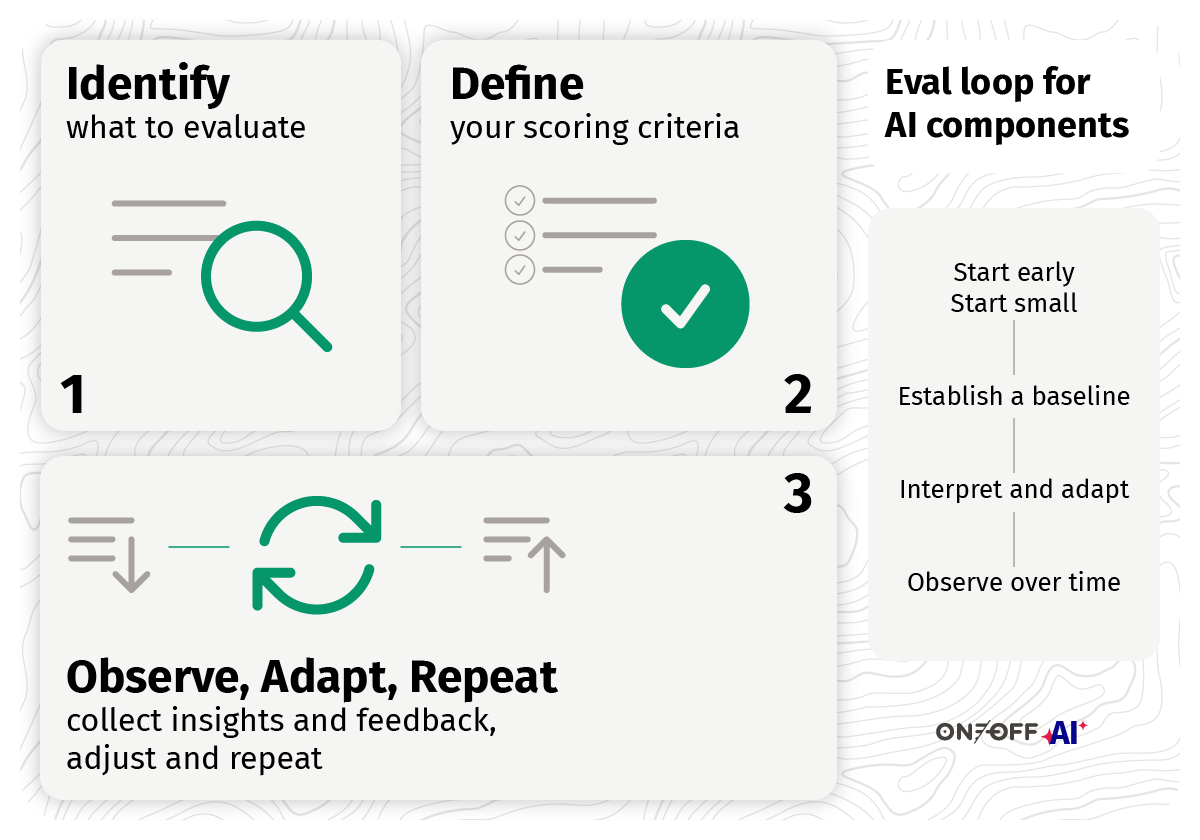
Step 1: Identifying What to Evaluate
Begin with the most business-critical behaviours.
Input and expected output(s) are pillars of testing. Just like creating traditional unit tests we want to define a set of possible inputs and possible outputs to evaluate our code (being a prompt or a trained model, or both) against.
Start by asking yourselves two questions:
- Can I figure out what the input would look like?
- Can I figure out a possible output given that input?
If you run a retrieval-augmented-generation (RAG) service, you probably care about both the retrieval step and the answer-generation step. Ask yourself whether you can imagine realistic inputs and whether you can articulate what a good answer looks like. Keep refining the scope until each testable unit has clear, memorable expectations. Remember, input and output examples can be sub-optimal.
Let's apply those questions to three common AI-based features:
| Application | Environment | Input(s) | output |
|---|---|---|---|
| RAG - retrieval | Stored text chunks | Question | Sorted list of text chunks |
| RAG - generation | LLM provider | Question + Instructions + Relevant chunks | Answer |
| Structured extraction | LLM provider | Text + Fields | Field + Value |
| Summary | LLM provider | Text + Criteria | Text |
Notice how RAG is split into retrieval and generation for clearer evaluation, while summary is considered an atomic action.
What if I cannot figure out the input? Well LLMs can be tasked to create a realistic input and output as far as you can describe what you expect!
Step 2: Defining Scoring Criteria
Scoring converts subjective impressions into measurable data. Your goal is to establish an initial baseline - fuzzy and broadly approximate: precise enough for comparison, but tolerant of variation. Let's put three questions down to guide us:
- What part of my AI-based feature should I address first?
- Do I have criteria (users would use) to judge the output? (e.g. based on content, similarity, rules)
- Can I measure how close the output is to what’s expected?
Continuing our comparison on RAG, structured extraction and summary feature evaluation we can identify what we think we should address in our evals and our scoring options.
| Application | What to score | Score |
|---|---|---|
| RAG - retrieval | How good we retrieve the parts of text | code-based: Context precision/recall |
| RAG - generation | How aligned we are to the user expectation? | LLM-based: Factual correctness, G-eval using criteria... |
| Structured extraction | Can we get those text out in a specific format? | code-based: Equality, Sub-string, BLEU, ROUGE,... |
| Summary | How much we respect the input criteria? | LLM-based: G-eval using generation criteria |
Code-based grading is deterministic and cheap; for instance, you might check that a summary contains a required keyword or that an extraction matches a regular expression or even use string similarity (e.g. BLEU, ROUGE). Large-language-model grading (or LLM-as-a-judge) is more flexible and scales well to nuanced tasks, though it costs more and adds its own variability. When using large-language models to grade an output remember to define the key aspects should be found in the response, e.g. the summary should include the “main concept”. Human grading remains the gold standard for subjective qualities such as style or persuasiveness, but it is the slowest and most expensive option. Mix all three methods where each is most appropriate.
Step 3: Observe, Adapt, Repeat
Traditionally, tests are executed in continuous integration pipelines. AI evaluations should be carried out during the development of your AI-based feature, when changes are applied to the feature, and periodically based on user activity and reported feedback.
Monitor user interactions and collect real-user feedback. Collecting feedback deserves its own write-up; the main point here is that you can infer/derive functional patterns based on recurrent interactions , such as repeated execution of the same tasks, or through direct feedback, like the famous thumbs-up and thumbs-down buttons.
Adapt the inputs and outputs of your evaluations based on the feedback, and adjust the scoring thresholds as your application evolves.
Even without feedback consider when is most appropriate for your application to re-evaluate, e.g. new models are out or checking smaller models to reduce costs.
| Application | When to re-evaluate |
|---|---|
| RAG - retrieval | - After reaching more than a thousand documents - After adding extremely similar documents to already existing ones - When users ask the same question a few times |
| RAG - generation | - When users ask the same question a few times - When supporting new LLMs |
| Structured extraction | - New fields added - New input document format |
| Summary | - When criteria changes |
Cost Advices
Not all evals cost the same. Code-based checks are nearly free, LLM-based grading incurs model fees, and human evaluation consumes time and resources. You cannot map every possible inputs therefore define less than ten input/output combinations to begin with. Start with lightweight tests that catch the worst failures early, then layer richer assessments where they add meaningful insight.
Observe and monitor the costs, you can do using tools like Langfuse or the LLM providers’ dashboard at worst.
Putting the Eval Loop into Practice
- Start early, create a few input and output pairs as you start working on your AI-based feature.
- Start small, identify a component of a set of AI-based components you can evaluate
- Establish a baseline, Define an initial set of evaluation criteria and score the outputs.
- Interpret and adapt, look at the results and adapt based on feedback, either coming from users or the evals
- Over time, the eval suite becomes an executable specification of how your product should work.
Icons from heroicons.
Human · No AI
The content was produced by humans with no AI involvement.