Rethinking Document Intelligence: Structured Extraction and the Primacy of Data Preparation
- Published on
- — 4 min read (~1.6k tokens)
We collaborated with experts from the IT and Knowledge Management unit of a multi-donor climate finance facility to enable automatic extraction of lessons learned and recommendations from a large corpus of project reports.
Lessons learned are insights gained from project experiences. Recommendations are actionable steps derived from these insights to improve future projects.
Traditional NLP pipelines fall short when text varies in phrasing and structure, as recommendations and lessons do. We used structured extraction instead: LLMs convert free-form report text into schema-compliant outputs (e.g. JSON, CSV, XML) guided by carefully crafted prompts, iteratively refined with user feedback.
The Challenge of Extracting Structure from PDFs
Extracting usable data from PDF sources remains a bottleneck:
- Heterogeneity of layouts: documents include multi-column text, tables, figures, annexes, and scanned pages.
- Fragmented tooling landscape: multiple parsers exist, but none performs consistently across all formats.
- Parser lock-in: Due to heterogeneous parser formats and interfaces, the coordinated use of multiple parsers on the same document remains challenging, often leading to the selection of a “least-worst” solution.
What do we mean by usable data? A textual representation that preserves metadata for traceability and maintains the integrity of the source text, including word order and layout elements such as headings. It focuses on what matters for the task, ignoring irrelevant pieces.
Once you get usable text out of those PDFs additional challenges emerge:
- Operational inefficiency: sending 100 pages to an LLM for extraction is often not viable due to cost and processes time;
- Semantic Redundancy: the same concept may be expressed multiple times across a document (e.g. summaries, main sections, annexes), often with slight variations, leading to repeated extraction of equivalent content;
- Semantic drift: key terms may take on different meanings depending on their context (e.g. “sustainability” in financial vs. environmental sections), making it difficult to maintain consistent interpretation during extraction.
A Parser-Oriented Approach to Data Preparation
To address these challenges, we adopted a parser-centric strategy based on an open-source platform designed to orchestrate document parsing workflows – Parxy - through a unified interface.
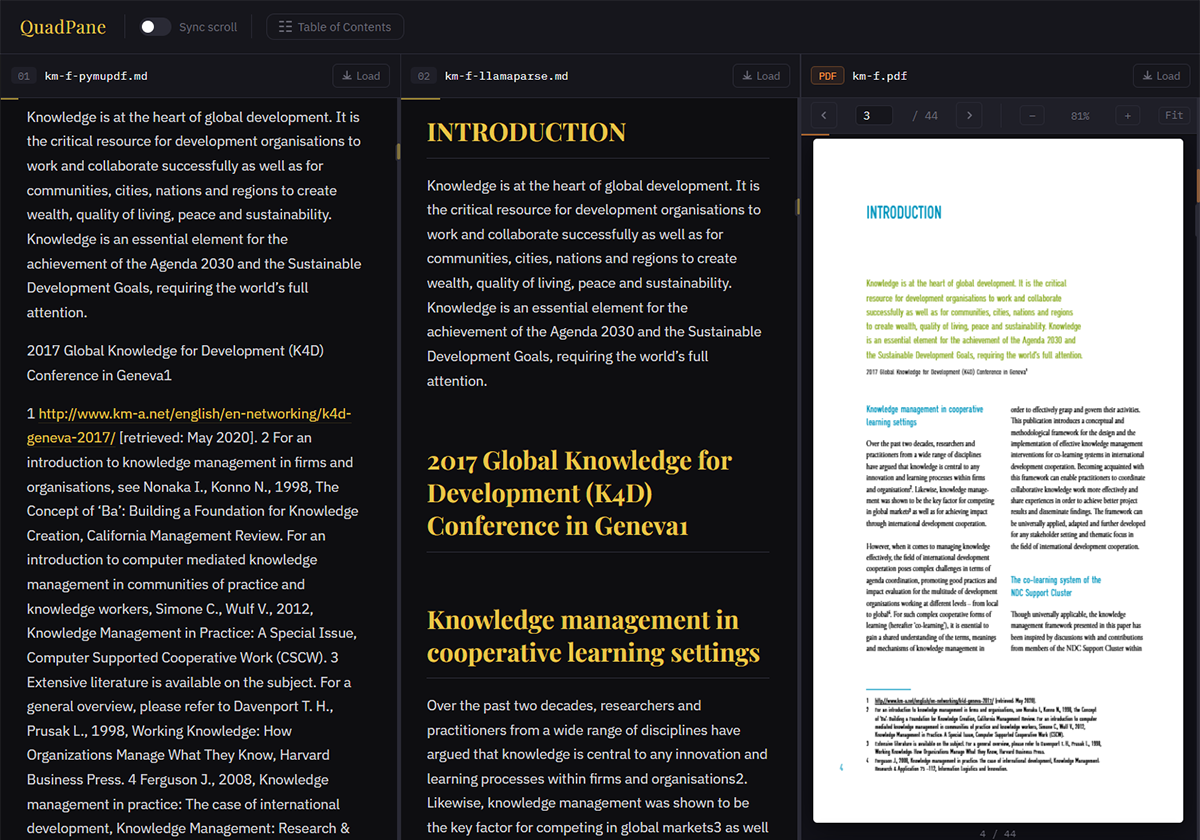
This strategy assumes that preserving word order and layout structure is a prerequisite for effective downstream processing. By maintaining the logical organization of the original document, it enables more coherent chunking and more precise retrieval, reducing ambiguity and mitigating the impact of semantic drift and redundancy.
To this end document parsing is decoupled from from downstream AI tasks, allowing greater control over data preparation improving the reliability of subsequent extraction workflow.
Key components include:
- Parser benchmarking: a curated library of parsers evaluated against different document structures.
- AI-assisted selection: dynamic selection of the most suitable parser at the page level.
- Workflow observability: full transparency over how each document is processed.
- Privacy controls: validation of sensitive content prior to AI ingestion.
- Abstraction layer: a standardized gateway that reduces integration complexity and mitigates lock-in.
This setup allows teams to shift attention from tooling constraints to the analytical value of content, enabling closer human control over extractions and fostering greater trust and AI uptake among domain experts.
From Raw Text to Structured Knowledge
Building on the parser infrastructure, the extraction workflow focus becomes identifying and structuring two key knowledge elements:
- Recommendations and
- Lessons learned
Beyond tuning for structured extraction, our data preparation approach gave us the ability to:
- Automate detection of relevant sections and paragraphs within diverse report formats
- Maintain direct connections between between extracted data and original sources (explainability)
- Guarantee that all information remains verifiable for future validation and reuse (traceability)
Observed Results and Practical Implications
The pilot provides initial evidence of the operational value of this approach. Across 16 projects and approximately 200 PDF documents, we processed 280 recommendations using the structured extraction workflow.
Compared to a fully manual approach, this cut processing time for extracting recommendations by ~60%, human validation included.
Beyond time savings, several qualitative improvements were observed.
Faster parser evaluation and selection
- Different parsing strategies can be tested and compared rapidly, enabling configuration choices based on document structural complexity (e.g. tables, columns, figures, annexes).
Improved targeting of relevant content
- Sections and paragraphs containing recommendations and lessons learned can be identified more efficiently across diverse document formats.
Source traceability
- Extracted elements can be directly linked back to their original textual location, supporting validation and auditability.
Resource optimization
- Token consumption can be monitored and optimized through coordinated use of parsers and selective processing.
Concluding Reflection
This experience suggests that structured extraction from textual reports may depend less on model sophistication alone, and more on how effectively the input data is prepared and contextualized.
In document-intensive domains such as international development cooperation, a parser-oriented approach could represent a foundational layer for scaling AI-supported knowledge workflows—potentially enabling more consistent learning, comparison, and reuse of insights across projects.
Human · AI Assisted
The content was produced by humans with AI providing minor help (e.g. grammar, translation) or generated segments (e.g. rephrasing or structuring) integrated by the author.